



場所を超えた世界~VRを活用した実践的学び【ススメ!コミュニケーションの新しいカタチ第5回】
2021/05/24

つい数年前まで研究室レベルの技術であったVR(バーチャルリアリティ)が、様々な場で利用されるようになりました。手術の訓練や水害などの非常事態の体験、失われた古代遺跡の再現などが良く知られていますが、VRをビジネスとして展開する企業が増えて、もっと身近な分野での利用が進んでいます。その中でコミュニケーションへの応用は期待の大きい分野です。本稿では、VRを用いてアバタとの身体的コミュニケーションを可能にした英会話練習システムについて紹介します。
ほとんどの日本人は6年以上英語の教育を受けているはずなのに、なぜ話せないのか、とは良く言われることです。文法偏重の教育のせいとか、発音を気にしすぎるからとか、色々言われますが、そもそも日常生活で英語を使う必要がなく、実地で使って覚える機会があまりに少ないことが大きな原因でしょう。英語の教材は山ほどありますが、生きた会話とは距離があります。後述するVRはこの状況を変える大きな可能性を持っています。
このシリーズでも度々取り上げられていますが、対面での会話は音声言語だけで成り立つものではありません。表情、身振りや身体的特徴、相手との人間関係など、様々な非言語情報がスムーズな会話に大きな役割を果たしています。コミュニケーションの研究によれば、対面の会話における情報の実に65%以上が非言語的なものとされています。私たちがLINEのメッセージで購入してまでLINEスタンプを使うのも、非言語情報を伝えたいからに他なりません。

現状の外国語会話の教材は、この非言語情報の活用が意識されているでしょうか。外国語会話には多くの勉強方法があります。スピーキングで言えば、会話テキストの台本を暗唱する、音声やビデオ教材の指示に従ってしゃべる、ナレータに合わせてシャドウィングする、会話学校で先生相手に話す、などです。インターネットの普及によりオンラインでモニター画面越しに先生と会話する方法も普及しつつあります。しかし、生身の会話相手が目の前にいない限り、非言語情報はほとんど使わないのではないでしょうか。
ここで非言語情報の代表的なものを表1に示します。この表に示したもの以外にも、会話相手と自分がいる場所が自分の部屋なのか、相手の家なのかといった環境の要素や、周りに第三者がいるかどうかも会話に影響を与えるでしょう。
表1 対話における非言語情報
| カテゴリ | 例 |
|---|---|
| 身体動作 | 表情、視線、身振りなど |
| 生理的行動 | くしゃみ、あくびなど |
| 対人距離、対人接触 | 個人空間、相手の方向と距離 |
| 周辺言語 | 声質、発声方法 |
| 身体的特徴 | 体形、容貌、性別 |
さらに、表1の中で特に重要な会話の進行を調整する「身体動作」に関して、心理学者のポール・エクマンは身体動作を役割により5種類に分類しています(表2)。視線が特出して色々な役割を有していることが分かります。
表2 エクマンによる身体動作の分類
| 分類 | 具体例 | 役割 |
|---|---|---|
| 表象 | 首振り、頷き、Vサイン | 言語に翻訳可能 |
| 例示子 | 指差し、指折り、視線 | 発話内容の精緻化 |
| 情感表示 | 表情、身振り、視線 | 情動の表出 |
| 調整子 | 相槌、視線 | 発話権の制御 |
| 適応子 | 頭を掻く、髪をいじる | 状況への適応 |
非言語情報を用いた会話をノンバーバル・コミュニケーションと言い、現実の会話では無い方が不自然です。英会話の練習でも非言語情報を使えた方が生きた会話に近づくはずです。しかし、オンラインで対面してもモニター越しでは多くの情報が欠落します。お互いに別空間にいるため、何かを指し示す動作をしてもその意図が伝わりにくいでしょう。一番問題なのが、視線を合わせることができないという点です。実際の会話では相手に見られることで、話すのが恥ずかしいといった心理的な緊張感が生まれますが、オンラインではそれが不足します。
PCはカメラがモニターの上部にあるため、画面の相手を見て話すと相手のモニターには下を見ている自分の顔が映ります。ニューススタジオなどで使われるハーフミラーをお互いに使って、カメラとモニターの光軸を合わせれば視線が合いそうですが、事はそう単純ではありません。TVのニュースキャスターは常にカメラ目線ですから、物理的には視線が合っているはずですが、私たちは「キャスターに見られている」とは感じないし、ましてや緊張もしません。 “視線が合っている”かどうかは高度に心理的な現象で、相手と空間を共有しない映像モニターではどうやっても再現ができないのです。

VRは空間の共有と非言語情報による実時間インタラクションを実装できるので、この問題点を大きく改善できる可能性があります。そこで私の研究室では、図1に示すようなユーザの視線とジェスチャを認識してアバタとの会話進行が変化するVR英会話練習システムを試作し、評価しました。このシステムはユーザの音声を認識するだけでなく、HMDに内蔵された視線計測装置で視線の向きを検出します。またHMDと手に持ったコントローラで首と手のジェスチャを認識します。ユーザの非言語情報に応じてアバタの発言内容を変えられます。例えばアバタの眼を見て話さないと、アバタが反応しないようにもできます。VRを使うと会話内容と符合した周囲環境を可視化できることも大きなメリットです。
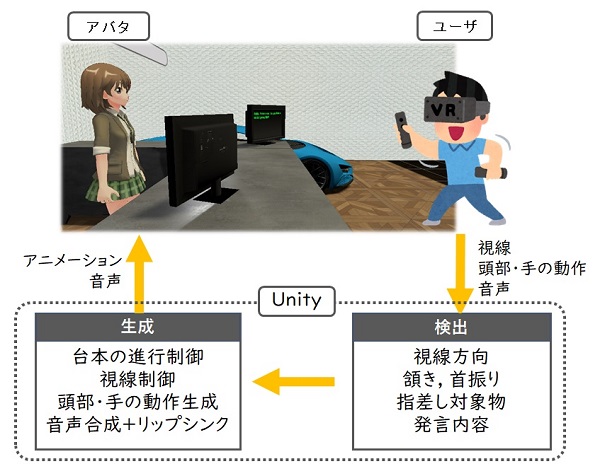
このシステムを用いて被験者に会話の練習をさせたところ、「アバタと面と向かうと恥ずかしい」、「眼を見て話すのは緊張する」といった評価が得られました。また、ジェスチャを認識するので、何かを指差したり、Yesと言う代わりにうなずくことで会話を進行させることができます。会話の本来の目的は相手との意思疎通ですから、単語が出てこなくても会話を続ける練習が大切です。今のところ、試作装置のアバタは、あらかじめプログラムされた応答を返すだけですが、AIによりアバタに知能を持たせることができれば、生身の人間との会話に非常に近い条件を作り出せるでしょう。留学しなくても同等の会話練習ができるかもしれません。今後、VR+AIで学びの分野が大きく発展することを期待したいと思います。
Profileプロフィール

小宮山 摂 青山学院大学名誉教授
東京大学工学部電気電子工学科卒業、同大大学院工学系研究科電気工学専攻修士課程修了。日本放送協会勤務を経て、2008年本学理工学部情報テクノロジー学科教授就任、2021年定年退職。ヒューマンインタフェース学会所属、専門はバーチャルリアリティ、ヒューマンコンピュータインタラクション、音響工学。


